Enabling analysis of California’s hiring and recruitment data
How the California Department of Human Resources (CalHR) worked with the Office of Data and Innovation (ODI) to increase analysis capabilities for the Examination & Certification Online System (ECOS).
The opportunity
The State of California has a quarter of a million employees, and each year hundreds of thousands of applicants go through the hiring and recruitment process, submitting millions of applications. They also take exams qualifying them for roles and go through interviews, resulting in hundreds of millions of events.
CalHR runs hiring using an application called ECOS. ECOS is designed for handling a high volume of hiring-related actions, but it is not well suited to in-depth analysis of its data. CalHR staff need to be able to ask questions of their data like:
- Which job classifications are receiving the most interest? Which are receiving the least?
- How diverse is our candidate pool for our job postings? Does it differ between classifications or departments?
- How successful was our latest job fair in driving applications?
For many years, CalHR had relied on a complex set of manually-run queries to support questions like the above. These queries were run by a single person with specialized knowledge. While this worked for some questions, this process was unable to scale. It was also time consuming and did not allow for exploratory analysis, and in-depth knowledge of ECOS remained siloed. Anytime someone had a new set of questions, a new query had to be manually and painstakingly constructed. This process severely limited CalHR staff’s ability to analyze their data and discover new insights.
CalHR had an appetite to solve these challenges and a desire to deepen their organization’s ability to make data-informed decisions. They approached ODI with that appetite, and ODI was happy to help them through our Modern Data Stack Accelerator (MDSA) service.
Our approach
The approach of MDSA is to empower agencies with the skills and tools that will let them improve access, collaboration, and automation. Rather than doing the work and handing over a solution, ODI centers training, mentorship, and pair programming opportunities to provide our clients with the skills and tools they need to both solve their current problem and build capacity to solve new problems going forward.
This approach is built into the MDSA service in a number of ways:
- Shifting analytics workloads to reliable, scalable, and secure cloud-based platforms
- Using modern engineering workflows like version control, code review, and automated testing for developing data pipelines
- Enabling stakeholders to connect directly to analysis-ready datasets, allowing them to self-serve questions and explore the data themselves without needing to make ad hoc requests of IT
Without ODI’s support, CalHR would have been responsible for designing every aspect of their approach, conducting market research, developing a plan, and gaining stakeholder buy-in with scarce resources. Their collaboration with ODI considerably accelerated the process, reducing what could have taken 2 years just to define the approach.
Data pipelines: a modern cloud-centered approach
We deploy a stack of industry-standard cloud software-as-a-service tools to build our data pipelines. The choice of stack components ensures that we are able to take advantage of the wealth of documentation and large user bases, while its modularity means that it is possible to swap out different components should they become a poor fit later down the road.
We used Fivetran as a low-code tool for copying primary data from the ECOS system to Snowflake, our data platform. This allows us to move the data to a more appropriate place for analysis, and we are able to drop sensitive information from the dataset during the move.
Once the raw data tables are in Snowflake, we use the dbt framework for transforming the data into analysis-ready datasets. This involves combining, filtering, and aggregating data from over 700 tables. This is a complex process, but the framework allows us to manage the complexity by tracking data lineage and enabling collaborative, version controlled queries.
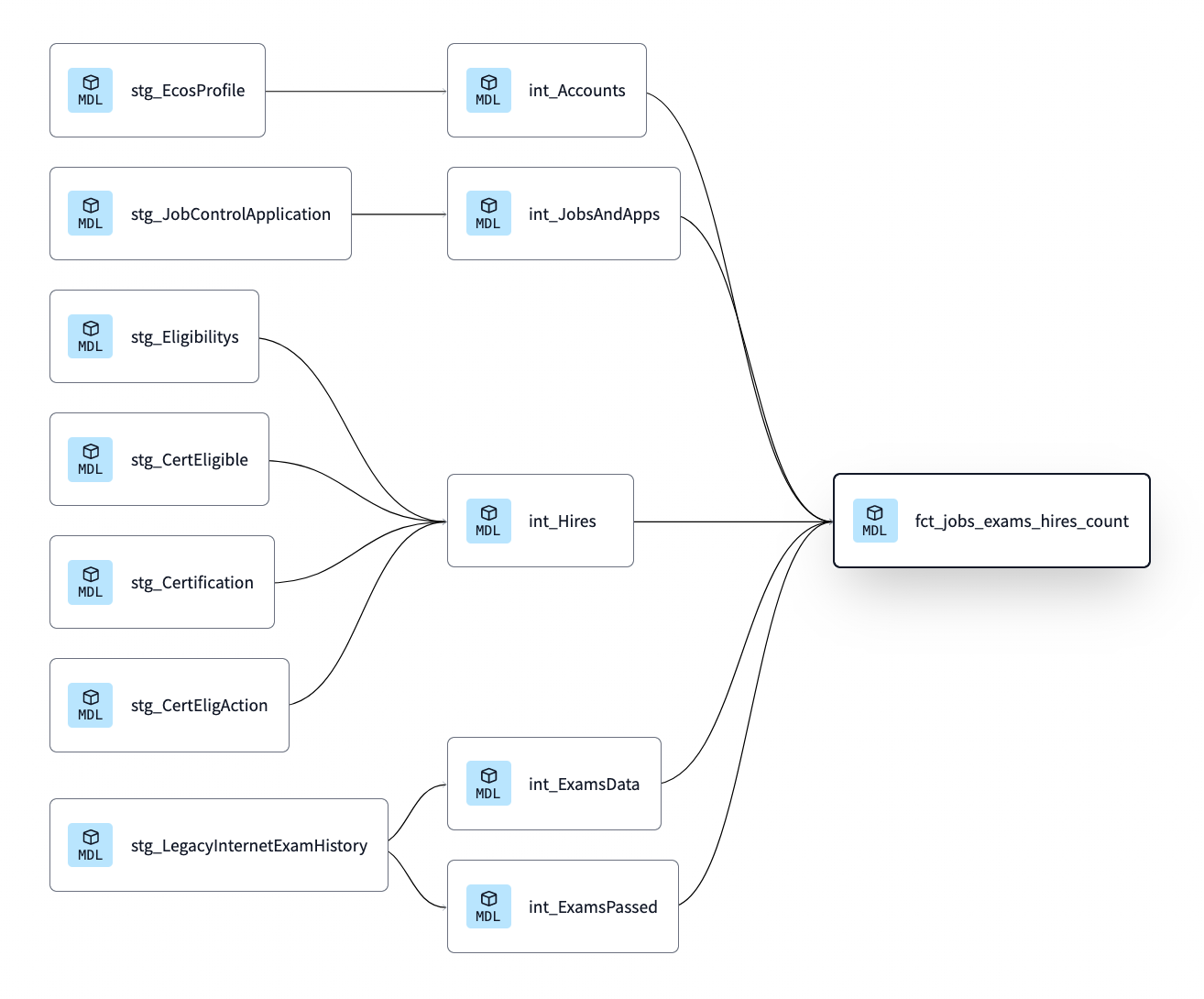
The data pipeline built using the above toolchain runs daily (at least), ensuring that everyone using the data is acting on the latest version.
Collaboration: using software engineering best practices
Just as important as the data tooling stack is the process. ODI treats data analysis as proper code, rather than an ad hoc process done by somebody else (who that “somebody” is can often be left unspecified). As code, analytics should be treated with industry-standard practices for software engineering using the version control systems, testing, and code review.
We worked with CalHR staff to host code in GitHub for the ECOS analysis project, which enabled:
- Safe development of new features in separate branches
- Robust testing of proposed code changes
- Peer review of code and configuration
- Documentation that is maintained by data analysts and lives near the code
- A history of how the project has evolved, allowing for easy rollbacks and auditing
- Issue tracking to allow for questions, bug reports, and strategic discussions about the code
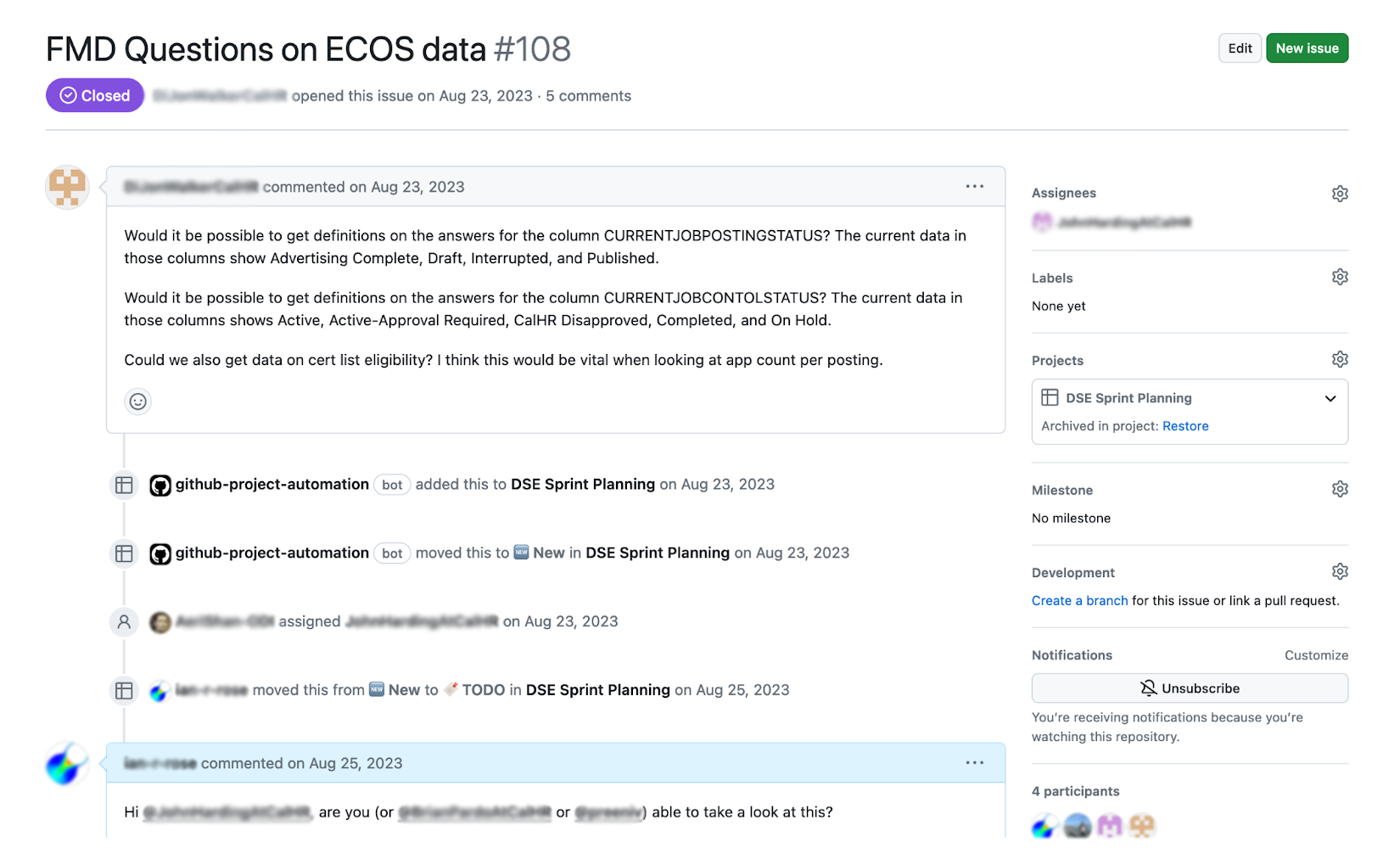
Reporting: enabling advanced analytics and discovery
The ultimate users of ECOS data analysis are not CalHR IT, but instead staff who need to reason about and report on hiring data (both within CalHR and across the state). A key goal of the ECOS analysis project is to enable that data usage without having all requests bottlenecked on one or a few IT staff who have many responsibilities and finite capacity for responding to all questions related to hiring data.
We’ve made the analysis-ready data tables produced by this project available to CalHR staff, who connect to them and have built dashboards using PowerBI. These dashboards provide self-service analytics to CalHR staff, allowing them to answer questions using the latest data that would have been slow and difficult to answer before. In the future, we hope to also allow state departments to access the same data to be able to better understand their own hiring processes.
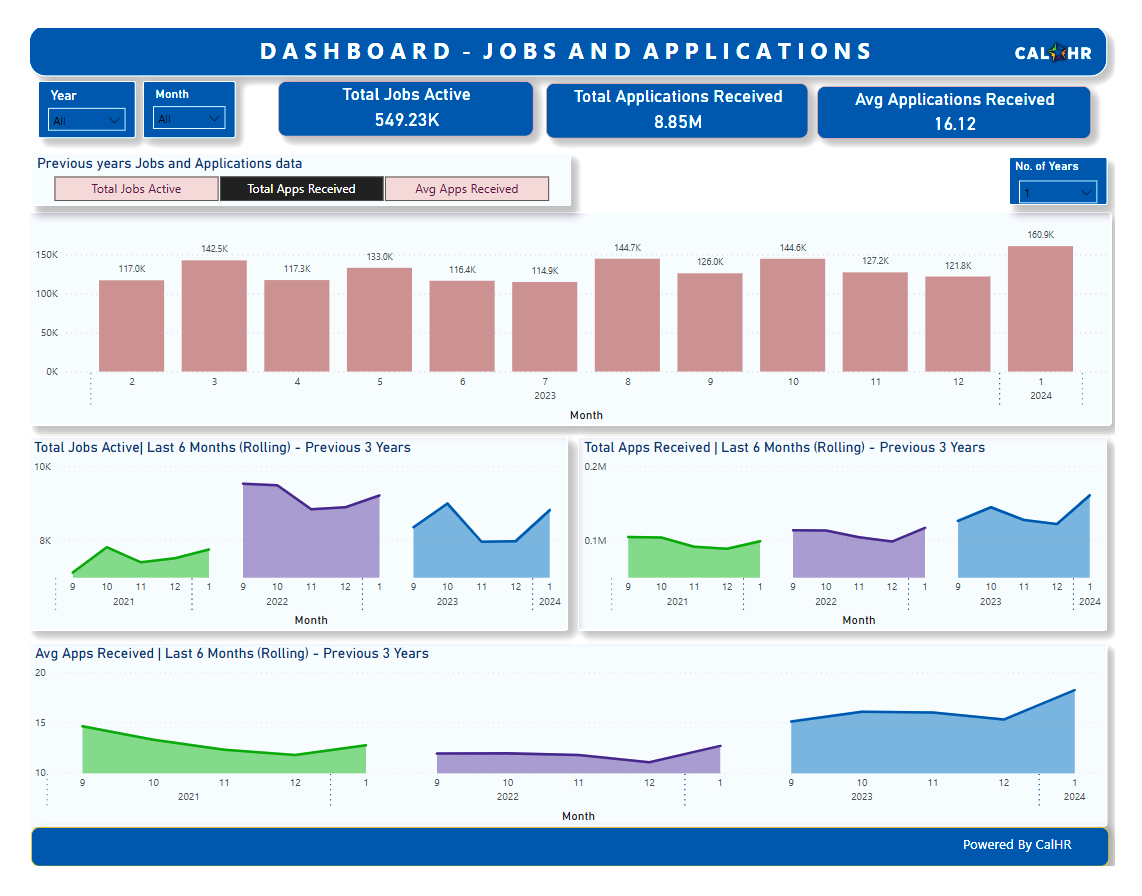
Impact
Previously, CalHR found it challenging to analyze ECOS data to answer questions about California’s hiring processes. The process was bottlenecked on a few IT staff with specialized knowledge. Producing reports from the data involved laborious construction of manual queries that could take days or weeks. One result of this is that staff frequently relied on out-of-date data rather than submit a new request for data.
After ODI’s MDSA project with CalHR, there is a scalable, cloud-based data pipeline which automatically generates analysis-ready tables on the latest ECOS data. Queries to produce the analysis-ready tables are developed using software engineering practices so there are robust data tests and a history of how they have evolved. Program staff can connect to these tables and self-serve analytics questions about California’s hiring data in close to real time.
Recommendations
ODI’s MDSA project with CalHR serves as a proof of concept for how the state can build a modern data pipeline for its hiring data. Further work should go in a few directions:
- CalHR can continue to socialize how to use and develop a code-first analytics workflow among both its IT and program staff. This includes further training in the use of GitHub (including code review, version control, and testing), as well as training in the use of PowerBI for reporting on the analytics.
- CalHR can now create data governance policies and practices on a robust foundation. The tools used make it easier to document datasets, visualize data lineage, and control access with fine-grained permissions. The concrete examples from the collaboration with CalHR allow them to have specific conversations about roles and responsibilities related to data so that knowledge of data and its appropriate use can be easily shared across the department.
- CalHR can bring in more data sources to their data pipeline, such as payroll and census data, allowing them to answer more sophisticated and cross-cutting questions about California’s workforce and hiring process.
Authors
Roles use the CRediT taxonomy.